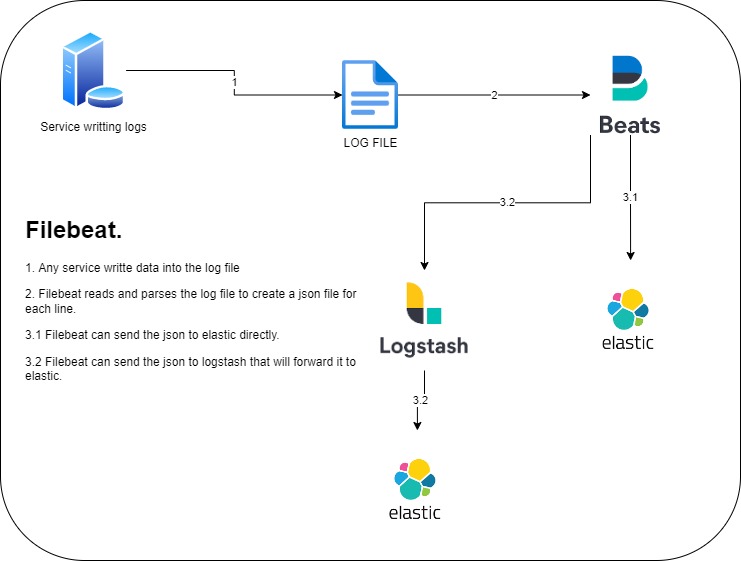
MongoDB Cloud Atlas
In this post, i will show you how to work with MongoDB Cloud. The good point is that MongoDB offers a free version that you can test with a limitation of 512 mega bytes which is a good starting point.
First go to https://cloud.mongodb.com/.
Log in with your google account or sign up.
You will be redirected to the home page
First of all we will create a New Organization
Organization can help to wrapp your projects and databases for instance in regions, departements or any idea you could have to separate your information. Click on the green button on the top left “Create New Organization”. Provide a name to your new organization.

Select your new organization and create new Project. Click on the green button on the top left “New Project”. Provide a name to your new project.

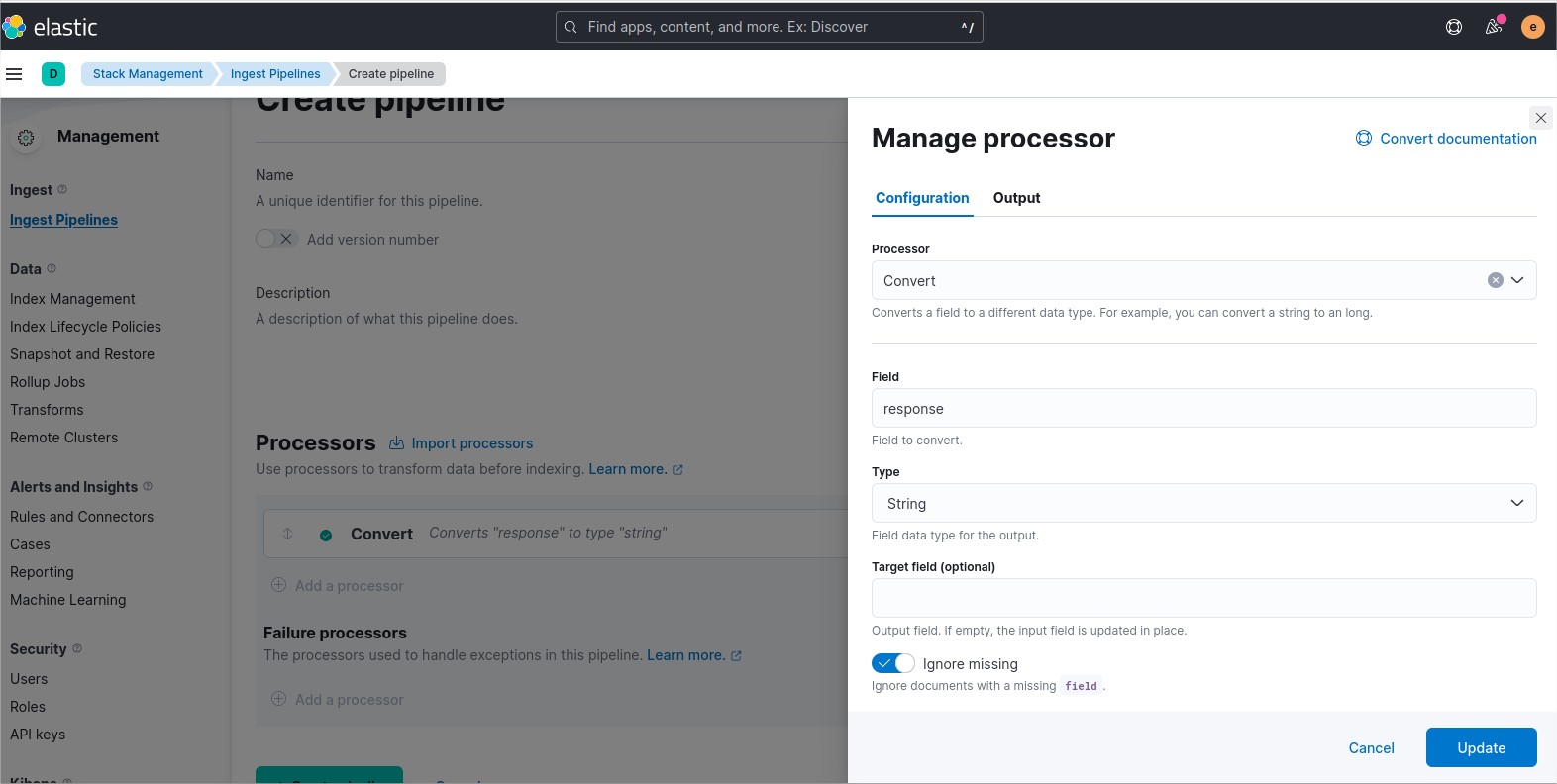
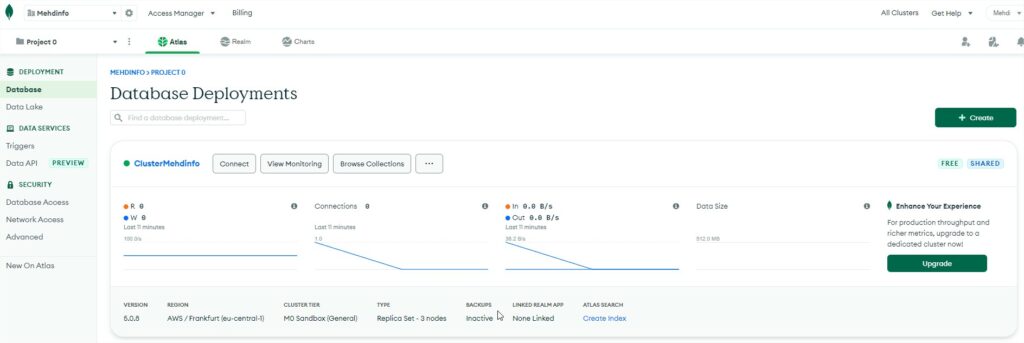
Select your new project and create a new Database. Click on the green button on the top left “+ Create”.

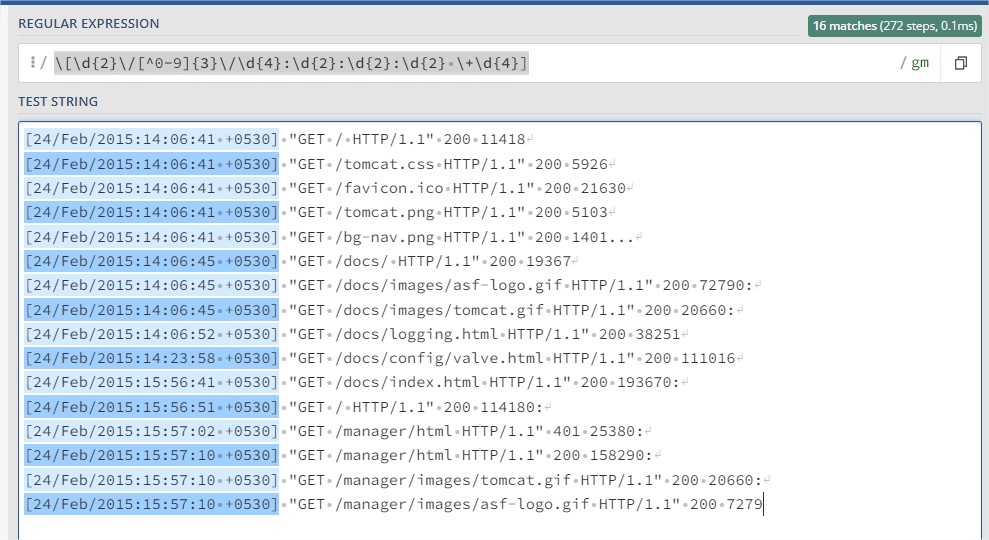
During the creation process, keep the cluster tier configuration to 512MB Storage and change de cluster name. The cluster will be composed of 3 loadbalanced mongodb servers.

Wait until the cluster creation process is completed. You will end up with cluster up and running.
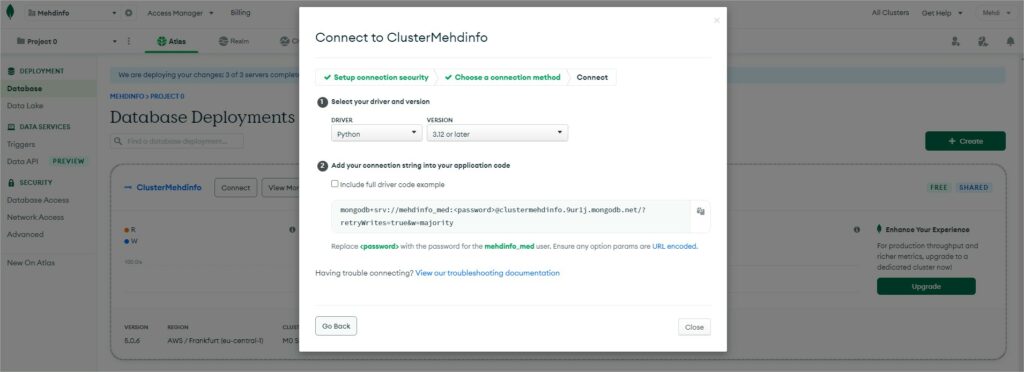
If you click on the button “Connect” and choose “Connect your application”, this will show some snippet code example for many different programming language such as Java, Python, GO, Perl, C, C++, C#, …
In my demo i will choose Python and a future post will be created with a git repo containing python code example to connect to mongodb, create a collection and apply CRUD operations to json documents.
Now if you select the cluster by clicking on it, you will arrive to the cluster overview page.
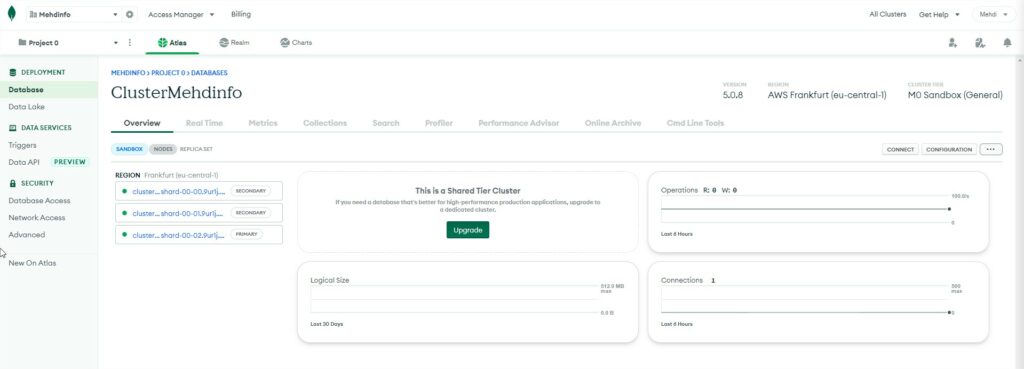
Select the “Metrics” tab and you will get an overview of the operation counters for the 3 servers.
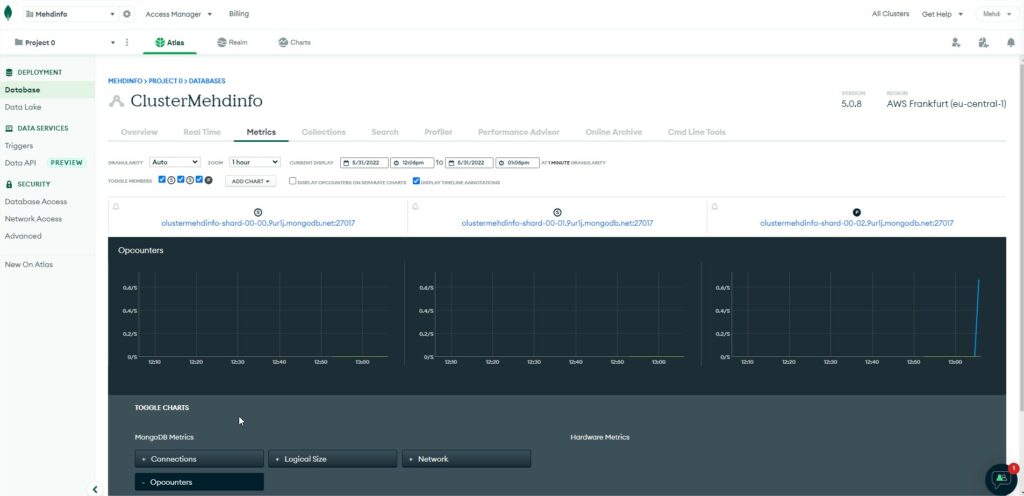
Select the “Collections” tab to browse data documents.
Select to “Search” tab to run DSL queries.
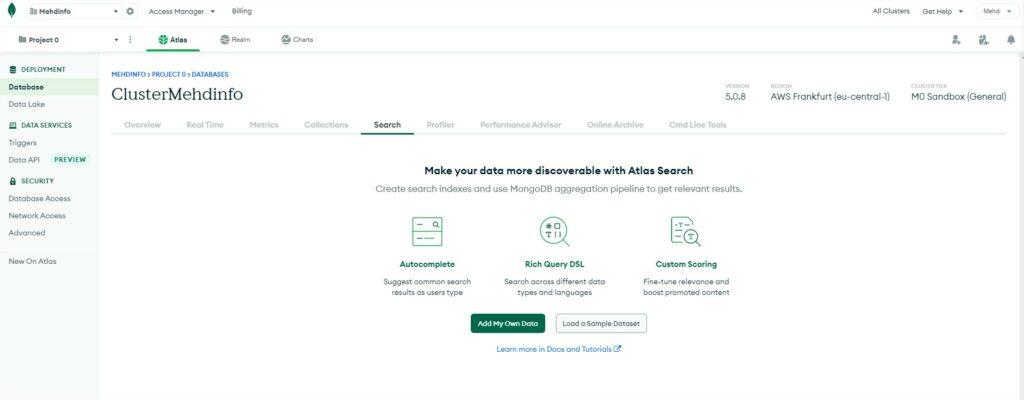
The “Profiler” tab, “Performance Advisor” tab, “Online archive” tab are only available with a paid plan so let’s skip those three options.
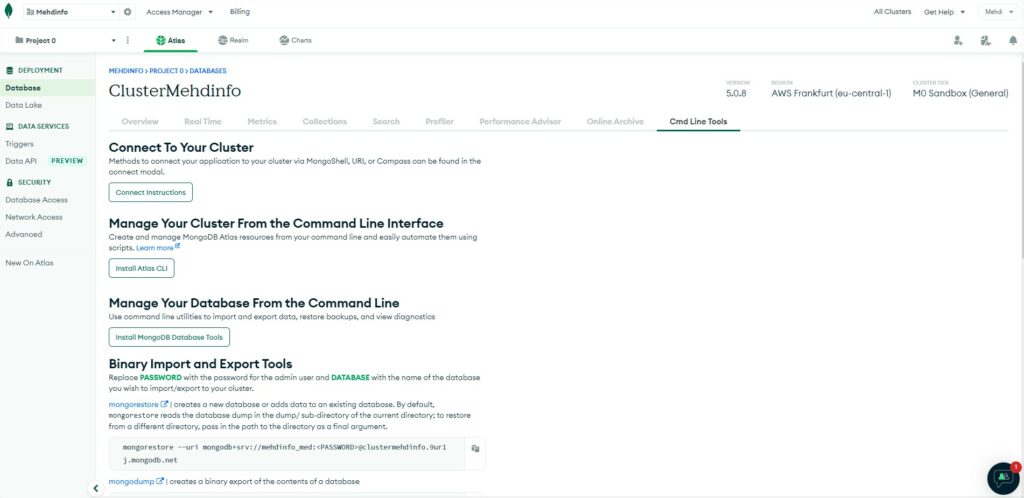
The last tab “Cmd line tools” will help you to see all the options to run command lines:
- Connect instructions: will help you to connect from shell or programming language or with MongoDB Compass (GUI to browse and manage your Databases).
- Atlas CLI: tool to install to manage DB by command line from brew for MacOS, yum or apt or tar.gz or deb or rpm for Linux or msi or zip for Windows.
- MongoDB Database tools: is a suite of useful command lines to install on MacOs, Linux or Windows.
- Mongorestore (binary exec file): is a tool to restore data comming from a dump (of Mongodump).
- Mongodump (binary exec file): is a tool to create binary dump from a database.
- Mongoimport (binary exec file): is a tool to import data from a csv, json, tsv file.
- Mongoexport (binary exec file): is a tool to export data to a csv, json file.
- Mongostat (binary exec file): is a tool to get metadata of a mongodb service.
- Mongotop (binary exec file): is a tool providing time run for read write transaction of mongodb service.
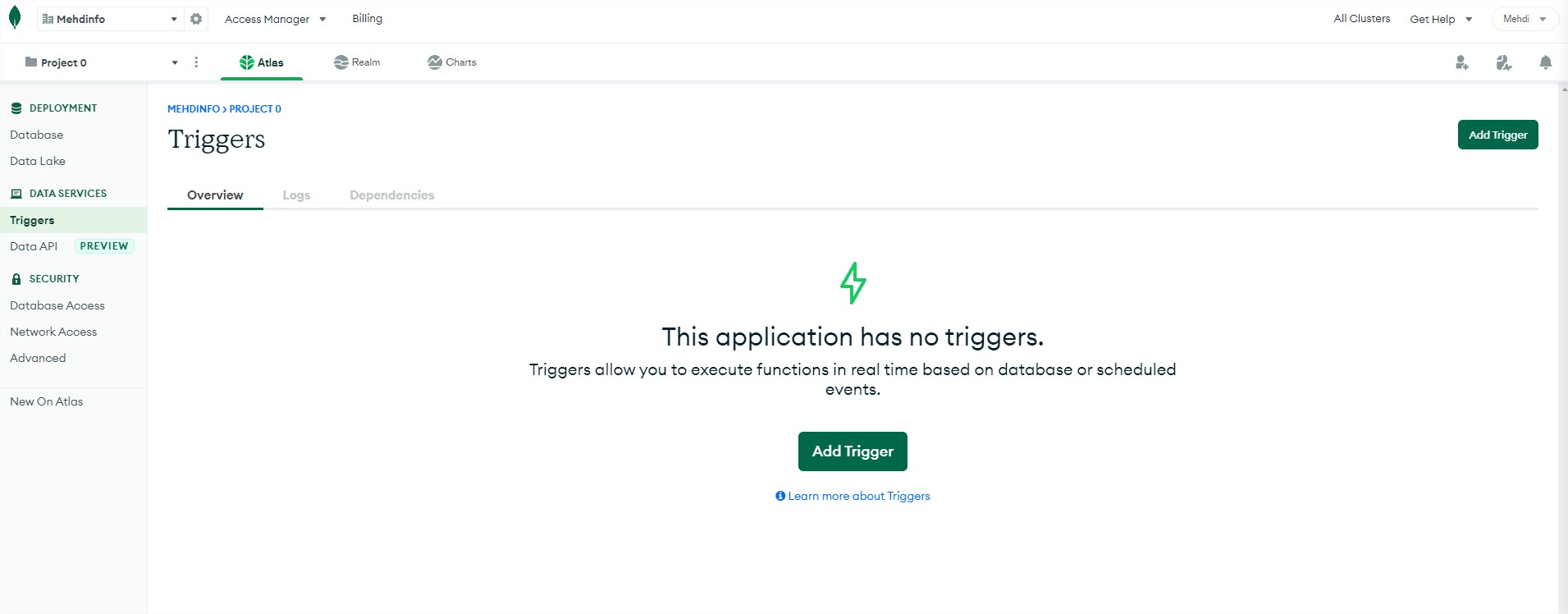
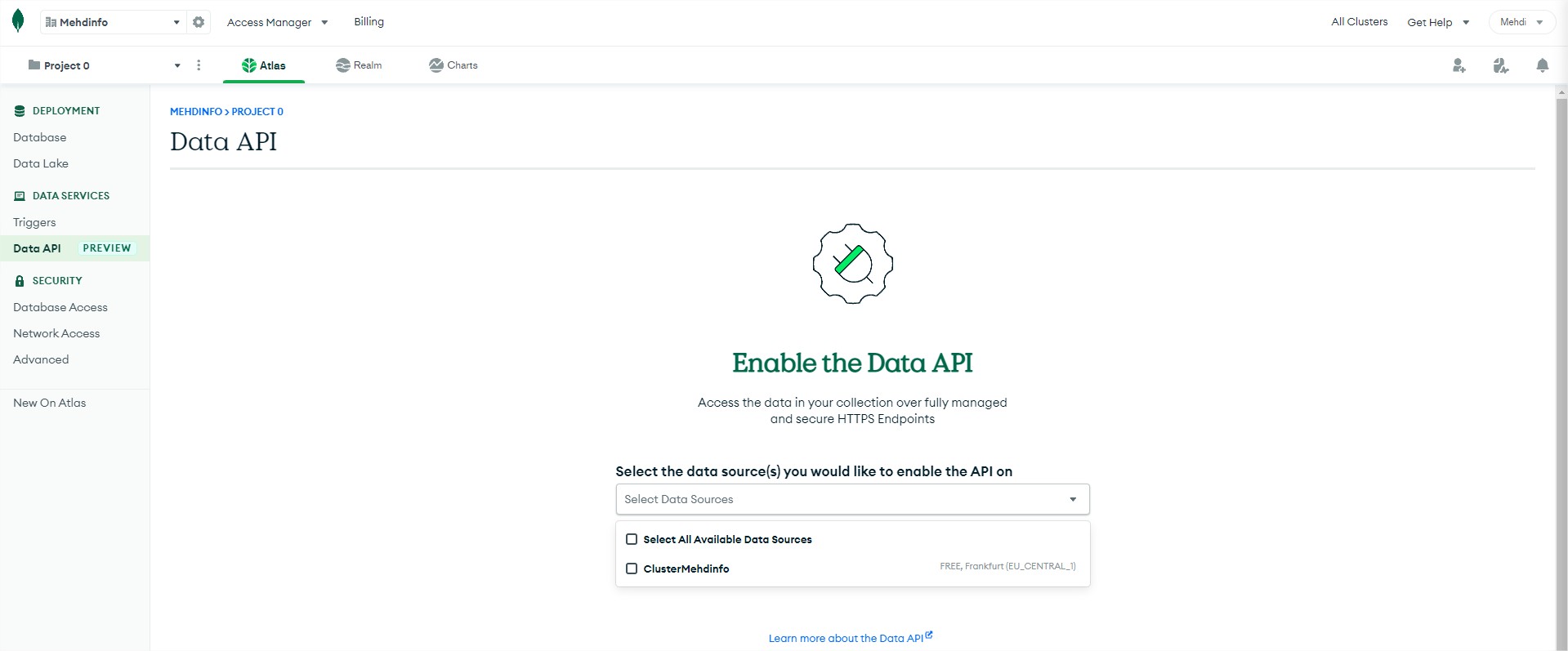
In the DATA SERVICES section, you will see two different options:
Triggers: allow you to run events based on crud operation that occured in a collection but you can also use the schedulded trigger to cron the code to execute.
Data API: allow you to operate actions on one of multiple collections.
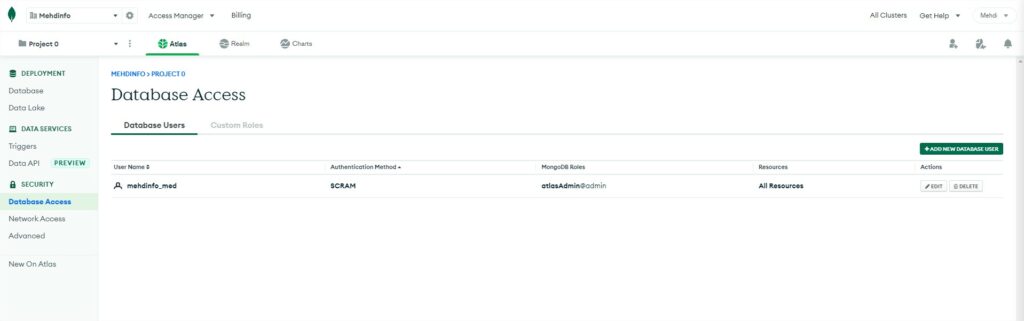
In the SECURITY section, you will see three different options:
Database access: this option is very important. This is where you will manage your IAM. You can create users with the option user/password access, of user/certificate access or link your Amazon WS IAM to manage your users. Each user can be configured with some basic roles attribution.
Network access: this option allows you to create an access list to filter the IP that will be allowed or denied to access the DB.
Advanced: this option allows you enable LDAP feature, data encryption and audit feature.
One last point i would like to mention is that if you would like to get a free to access any mongodb, i suggest you to download this free tool “MongoDB Compass”, you find it here ==> https://www.mongodb.com/products/compass
This concludes this small topic about Cloud Atlas.